 # Table of contents
```{toctree}
:maxdepth: 2
:caption: Contents:
installation.md
basic_usage.md
advanced_usage.md
tutorials/index.md
```
# Overview
Neural networks have emerged as powerful tools to understand the functional relationship between genomic sequences and various biological processes. However, current practices of training and evaluating models on genomic sequences may fail to account for the widespread homology that permeates the genome. Homology spanning train-test data splits can result in [data leakage](https://en.wikipedia.org/wiki/Leakage_(machine_learning)#:~:text=In%20statistics%20and%20machine%20learning,when%20run%20in%20a%20production), potentially leading to overestimation of model performance and a reduction in model reliability and generalizability.
# hashFrag
# Table of contents
```{toctree}
:maxdepth: 2
:caption: Contents:
installation.md
basic_usage.md
advanced_usage.md
tutorials/index.md
```
# Overview
Neural networks have emerged as powerful tools to understand the functional relationship between genomic sequences and various biological processes. However, current practices of training and evaluating models on genomic sequences may fail to account for the widespread homology that permeates the genome. Homology spanning train-test data splits can result in [data leakage](https://en.wikipedia.org/wiki/Leakage_(machine_learning)#:~:text=In%20statistics%20and%20machine%20learning,when%20run%20in%20a%20production), potentially leading to overestimation of model performance and a reduction in model reliability and generalizability.
# hashFrag
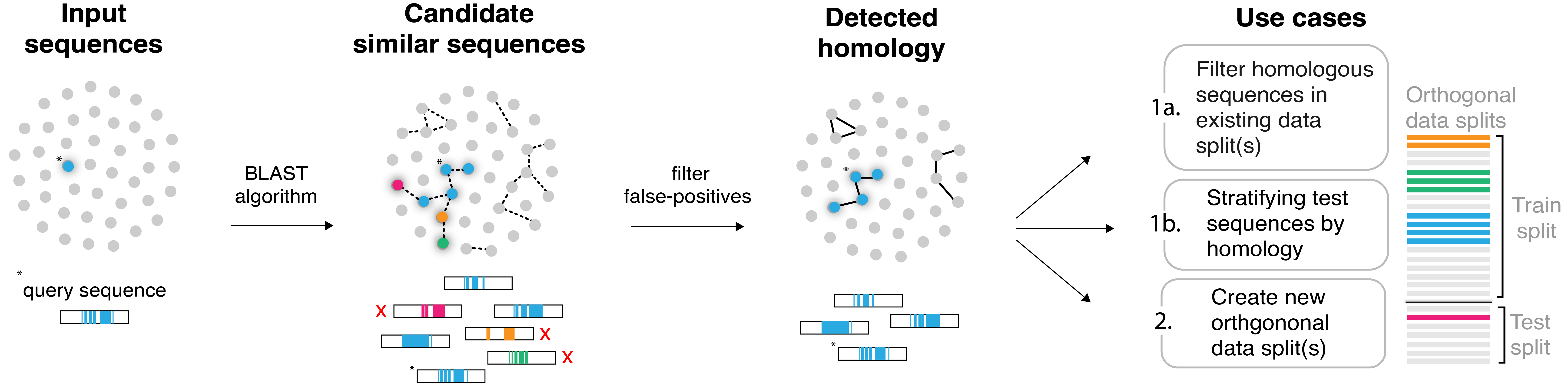 hashFrag is a scalable command-line tool to help users address homology-based data leakage during model development. The general workflow involves identifying “candidate” pairs of sequences exhibiting high similarity with [BLAST](https://blast.ncbi.nlm.nih.gov/Blast.cgi), filtering these candidates based on a specified similarity threshold, and then using the resulting homology information to mitigate the potential occurrences of data leakage in existing or newly-created splits.
Local alignment scores are used to quantify the degree of homology between a pair of sequences. By default, the alignment score will be derived from the top BLAST alignment result for a pair of sequences, which we refer to as `lightning` mode (see Basic usage). However, users also have the option to manually compute alignment scores to be used in downstream steps for added control over the homology search process. This version, referred to as `pure` mode, can lead to improved recall when using exact alignment scores (see Advanced usage and `/tutorial` for more details).
---
# Get started
[Installation](installation.md)
---
[Basic usage](basic_usage.md)
There are 3 primary use cases of hashFrag:
1. **Filter leakage from existing splits**: Remove test sequences homologous to the training set
2. **Stratify test set by homology**: Analyze model performance across different similarity levels
3. **Create homology-aware splits**](basic_usage.md#creating-orthogonal-splits)**: Generate train/test splits with no homology leakage
---
[Advanced usage](advanced_usage.md)
The basic usage commands execute hashFrag pipelines composed of a series of modules. For added flexibility, these modules can be called independently. This is useful for utilizing exact local alignment scores (Smith-Waterman algorithm) instead of the heuristic aligment scores provided by BLAST.
For large-scale applications of hashFrag, we provide an additional high-performance computing (HPC) mode, which generates array job scripts that can be executed on remote servers (i.e., cluster computing nodes).
> hashFrag currently supports the following job schedulers: SLURM, SGE
---
# Paper
Check out our [preprint on bioRxiv](https://www.biorxiv.org/content/10.1101/2025.01.22.634321v1) titled, "*Detecting and avoiding homology-based data leakage in genome-trained sequence models*", for more details.
hashFrag is a scalable command-line tool to help users address homology-based data leakage during model development. The general workflow involves identifying “candidate” pairs of sequences exhibiting high similarity with [BLAST](https://blast.ncbi.nlm.nih.gov/Blast.cgi), filtering these candidates based on a specified similarity threshold, and then using the resulting homology information to mitigate the potential occurrences of data leakage in existing or newly-created splits.
Local alignment scores are used to quantify the degree of homology between a pair of sequences. By default, the alignment score will be derived from the top BLAST alignment result for a pair of sequences, which we refer to as `lightning` mode (see Basic usage). However, users also have the option to manually compute alignment scores to be used in downstream steps for added control over the homology search process. This version, referred to as `pure` mode, can lead to improved recall when using exact alignment scores (see Advanced usage and `/tutorial` for more details).
---
# Get started
[Installation](installation.md)
---
[Basic usage](basic_usage.md)
There are 3 primary use cases of hashFrag:
1. **Filter leakage from existing splits**: Remove test sequences homologous to the training set
2. **Stratify test set by homology**: Analyze model performance across different similarity levels
3. **Create homology-aware splits**](basic_usage.md#creating-orthogonal-splits)**: Generate train/test splits with no homology leakage
---
[Advanced usage](advanced_usage.md)
The basic usage commands execute hashFrag pipelines composed of a series of modules. For added flexibility, these modules can be called independently. This is useful for utilizing exact local alignment scores (Smith-Waterman algorithm) instead of the heuristic aligment scores provided by BLAST.
For large-scale applications of hashFrag, we provide an additional high-performance computing (HPC) mode, which generates array job scripts that can be executed on remote servers (i.e., cluster computing nodes).
> hashFrag currently supports the following job schedulers: SLURM, SGE
---
# Paper
Check out our [preprint on bioRxiv](https://www.biorxiv.org/content/10.1101/2025.01.22.634321v1) titled, "*Detecting and avoiding homology-based data leakage in genome-trained sequence models*", for more details.